This project implements a Machine Learning (ML) pipeline for the Adver-City synthetic dataset. The dataset is designed for investigating cooperative perception in autonomous vehicles. Overall, this project enables efficient, reproducible modelling of the Adver-City dataset through ML workflows. We have chosen to train a model to identify weather conditions (clear, fog, rain) from nighttime images.
Note: full GitRepo available here.

Operation
The project is organized into four main stages. Depending on what your goal is (data exploration, ingestion, or training), the notebooks indicated below describe how to run each stage of the workflow.
Initial Data Exploration: A detailed readme has been provided to describe the Extract, Transform, and Load (ETL) process. This is complemented by a notebook that walks through an exploration of the dataset.
Data Ingestion Pipeline: The pipeline selectively ingests data from the FRDR remote server, extracts files based on a sampling plan, creates labels, and generates clean train/val/test splits. A detailed notebook describes the data ingestion pipeline, including how data is ingested, sampled, and prepared for training.
Data Management Pipeline: A detailed notebook describes the data management pipeline, including how the data is cleaned and transformed. A custom Dataset class is defined for use with PyTorch DataLoader. Some Preprocessing (resizing, normalization, and augmentation) is applied to the data.
Training and Testing Pipeline: A detailed notebook describes the training and testing pipeline, including how to train a model, save checkpoints, and evaluate performance on a test set.
Project Structure
We have organized the project into a modular structure to facilitate efficient development and reproducibility. The main directories and their purposes are as follows:
pytorch_project_advercity/
├── README.md
├── requirements.txt # required packages and their versions
├── venv/ # virtual environment for project dependencies
├── config/
│ └── config.json # all configuration parameters stored here
├── data/ # raw and processed data stored here
│ ├── index/
│ ├── raw/
│ ├── ready/ # train, val, test splits stored here
│ └── sampled/
├── docs/
│ └── README_ETL.md
├── exploration/
│ ├── __init__.py
│ ├── utils.py
│ └── data/
├── master_scripts/ # useful master scripts for data pipelines
│ ├── __init__.py
│ ├── data_management_pipeline.py
│ ├── ETL_pipeline.py
│ └── __pycache__/
├── notebooks/ # notebooks for each stage of the workflow
│ ├── data_ingestion_pipeline.ipynb
│ ├── data_management_pipeline.ipynb
│ ├── initial_explore.ipynb
│ ├── training_pipeline.ipynb
│ └── img/
├── results/
│ └── # models and their training results saved here
├── src/ # the main source code for the project
│ ├── __init__.py
│ ├── __pycache__/
│ ├── data_management/
│ ├── ingestion/
│ ├── testing/
│ ├── training/ # model definitions stored here
│ └── utils/
Results
We trained a Convolutional Neural Network (CNN) model to classify weather conditions (clear, fog, rain) from nighttime images. The architecture of the model can be found in the src/training/model_definitions.py file.
Models and metrics are saved incrementally during training (using checkpoints) and the best model is updated along the way. Below shows an example of the results directory structure for a single training run. Each training run is saved in a separate subdirectory with a unique name (based on the experiment name defined in the config file) and timestamp.
results/
└── advercity_weather_classification_128x128_20260322_110258/
├── best_model.pt
├── config.json
├── final_model.pt
├── metrics.json
└── checkpoints/
├── epoch_1.pt
├── epoch_2.pt
├── epoch_3.pt
└── latest.pt
Training and Validation
The model was trained on the train set split and validated on the val set split. The training process was monitored using the validation set to track performance and prevent overfitting.
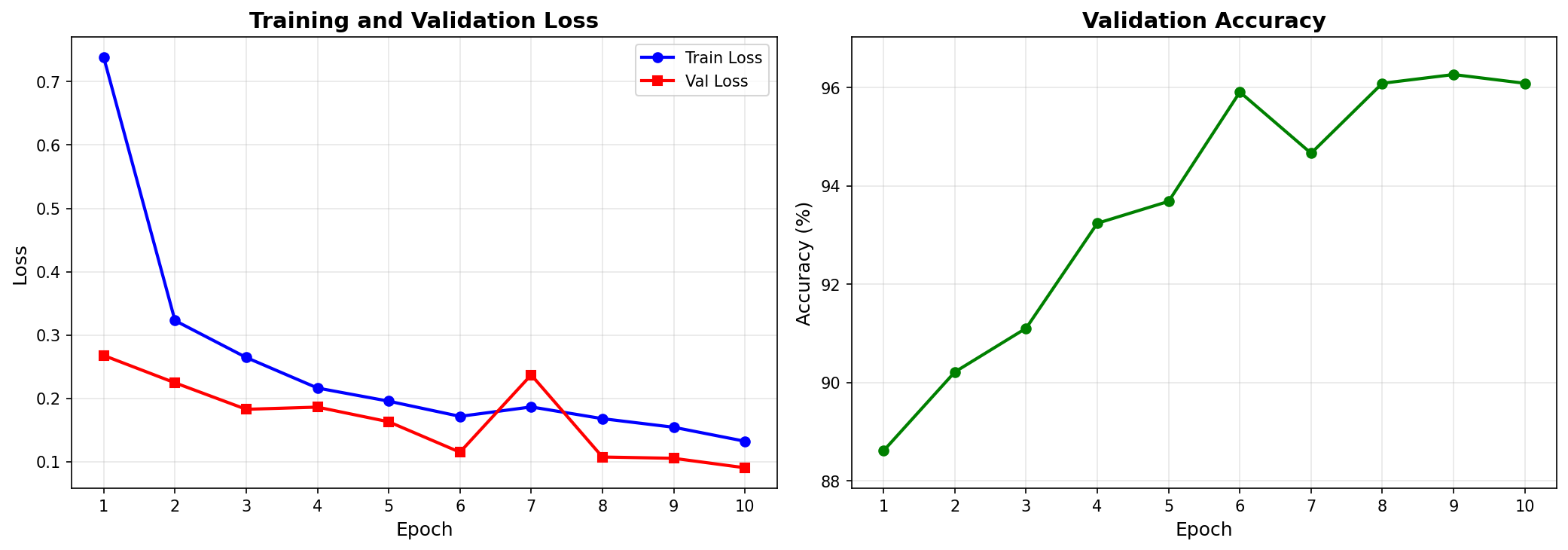
Testing
As shown in the Training and Testing Pipeline notebook, the model above was tested on a separate test set split. The accuracy of the model on this split was 96.26%, consistent with the validation performance.
Conclusion
In this project we implemented a complete ML workflow for the Adver-City dataset, including data ingestion, data management, training, and testing. The modular structure of the codebase allows for efficient development and reproducibility. The trained model achieved high accuracy in classifying weather conditions as clear, foggy, or rainy from nighttime images, demonstrating the effectiveness of our approach.
References
Karvat, M., & Givigi, S. (2024). Adver-City: Open-Source Multi-Modal Dataset for Collaborative Perception Under Adverse Weather Conditions. arXiv preprint arXiv:2410.06380.